Open data for humans
February 18, 2018
This article is a precursor to “12 reasons your open data isn’t really open”, a talk I’ll give at the Open Belgium conference on 12 March 2018 in Louvain-la-Neuve, Belgium. In this article I only touch a few of the reasons why I think a lot of open data isn’t really open. If you want to hear about all the other reasons, come see me talk at Open Belgium. Or wait untill I post my talk slides here :-)

One of my favorite projects I did while working as a data journalist for newspaper De Tijd was Identified: the Members of Parliament Doing Nothing (in Dutch). At the start of the new parliamentary year, the President of the Flemish parliament, Jan Peumans, had said that some of his colleagues in the parliament ‘were doing nothing’. A bold statement, that put me on a quest to find out who these lazy MP’s were.
I went looking for data on MP’s activities on the website of the Flemish parliament. I knew the parliament published data on everything that happens in parliament as open data. So I started digging through their open data API.
Now, I know how to program a little bit (more than most other journalists, in any case). But after half a day of trying to find out how I could get the data I wanted, I gave up on the API. I would have needed to get the list of MP’s, consume the json or xml that the API spit out (I don’t really like these data formats), get the ID’s of the MP’s, scan for their ID’s in meeting minutes, parliamentary document authorships, … For all of which I would have had to make a lot of API calls for and process the results.
So I gave up, and instead went for a more dirty, but much quicker alternative: I just scraped the html of the parliament’s website. For every MP the website offers a little profile, on which you can click through to find out how many documents the MP filed and how many times he or she had said something in a commitee or plenary meeting. In an hour or two, I had the data I needed and could start analysing and visualising.
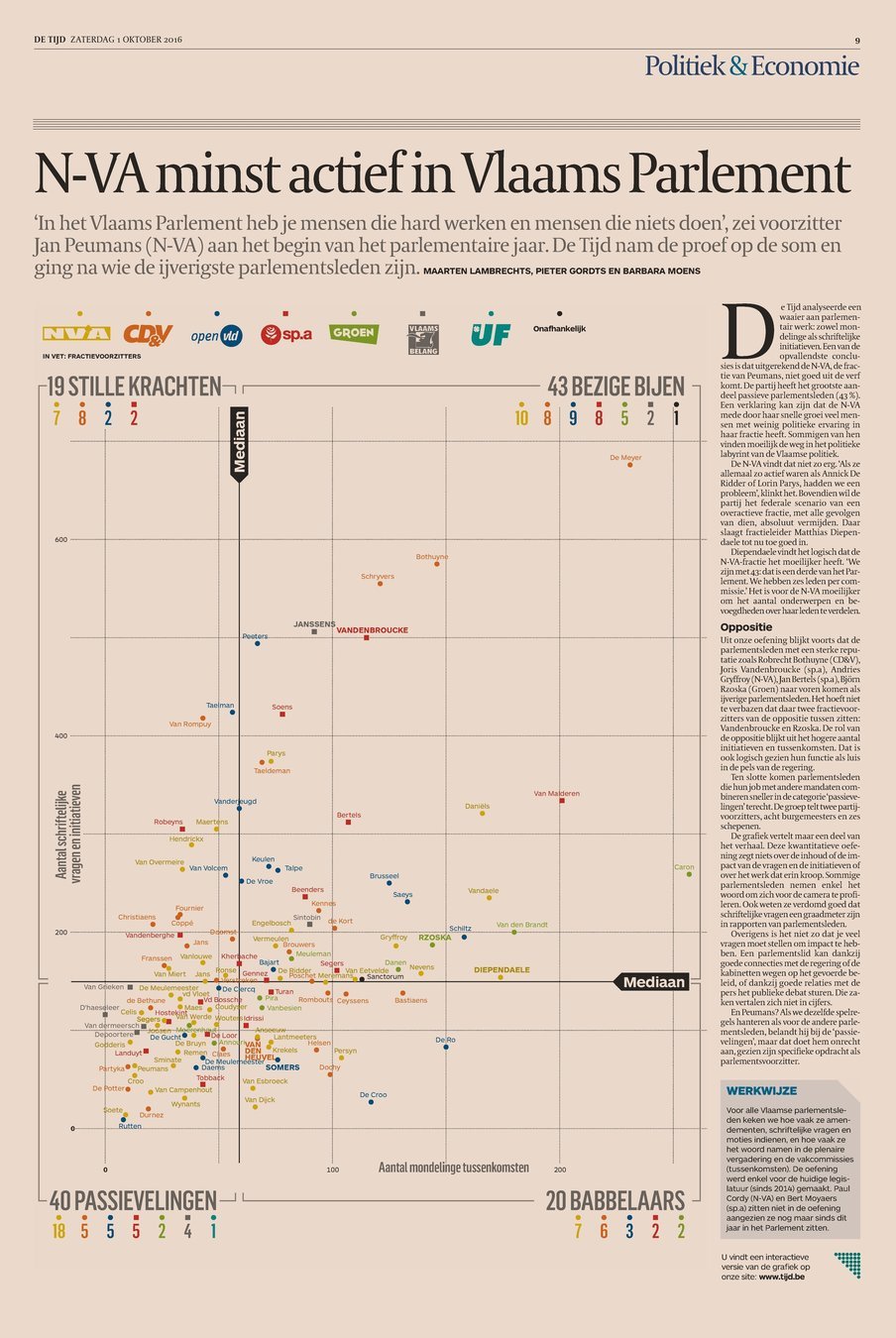
The scatterplot with the Flemish MP's activities as published in the newspaper. The passive MP's are in the bottom left corner of the chart. Check the online version or read the making of (includes code!)
Machine readable open data is good and necesarry: no doubt about that. But what I learned from the MP’s data case is that if you want as many people as possible using your open data (and who doesn’t?), you have to realise that only a minority of people are programmers who can approach your data with code.
Part of the definition of open data from the Open Knowledge Foundation states that
‘…everyone must be able to use, reuse and redistribute — there should be no discrimination against fields of endeavour or against persons or groups.’
I think in many cases non-technical people are excluded from access to open data. What if you want that data behind the API, but you don’t know how to speak to it?
So what could data publishers do to overcome this? Well, don’t only give users an API (data for machines), but also publish data for humans. This means publishing data
- as a table or spreadsheet
- with clear visualisations
- in a format most people know how to open (I’d go for csv)
- with explanations about the data in language non-experts can understand
Of course generating this human readable data for all data sets would mean a lot of extra work for open data publishers. But I think a lot of publishers know which of the datasets they publish are of most interest to some specific audiences (journalists) or the general public.
Why not go the extra mile with those datasets and turn the data for machines into some data for humans? I’m sure your data will be used more. Imagine the Flemish parliament publishing a table keeping track of the MP’s with the least activities. That would be a very popular dataset.